Show, Don't Tell: How Examples Boosted Our LLM Data Extraction Accuracy from 61% to 97%
Ever banged your head against the wall trying to get consistent results from LLMs? Yeah, me too. We've all been there – spending countless hours fine-tuning prompts, testing different document parsing libraries, and crafting supposedly "perfect" solutions... only to end up with mediocre results. But here's the thing: sometimes the simplest tricks pack the biggest punch. In this post we'll cover how just simply providing an example increased complex data extraction accuracy from 61% to 97%.
The Challenge: Complex Utility Bills
Let me walk you through a real-world example. While building Limai's data extraction product we encountered many cases of complex data extraction from PDFs. One of such cases was a Proof of Concept in which we needed to extract utilities data from invoices which had two challenges:
- They were in Czech and non english languages tend to hinder data extraction.
- Some of the values that needed to be extracted where the sum of individual data points.
For example, if you would like to extract from the below utility invoice the energy consumed for Heating (Teplo in Czech), you actually need to extract the sum of the two highlighted rows/values. Same for Cooling (Chlad), Waste (Odpad), Water (Vodné), and Sewage (Stočné).
Additionally, we needed to extract other type of data like contract reference, address, period of the invoice (in a specific date format), address of the store, and service provider.
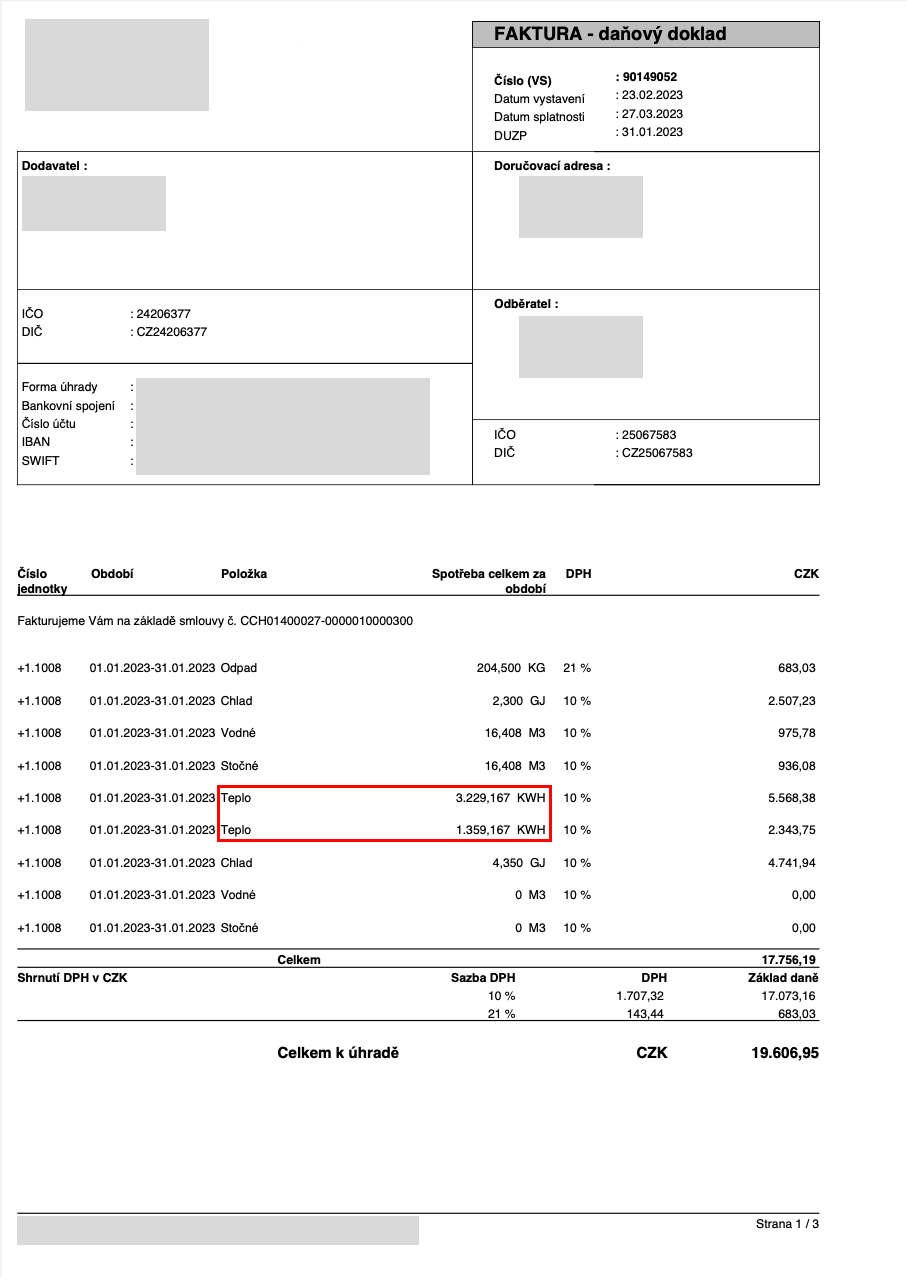
At the time the version of Limai we had in production was doing well on simple documents, but for this more complex scenario, we could tell from running the data extraction on a few documents that the results were not great.
What did we do? What we've recently been sharing in our post about Minimum Viable Models:
- We build a simple test dataset
- We iterated on the model / approach
Building the benchmark
In the spirit of keeping things simple, we used a straightforward approach. We had 36 files we could use for the Proof Of Concept, which were divided in 3 files types (12 each). In total we wanted to test extracting 27 data values, 11 for file type 1, 9 for file type 2, and 7 for file type 3. That added up to 324 individual data points that we can use as our test set to check how accurate the extraction is.
To create the test set we use the model we had in production at that moment and then manually review the extraction and corrected the results where needed. Through this process we created our ground truth test set. This part is of course boring, and tedious, but this is the work that it takes to be able to systematically evaluate and improve your models. Don't be lazy! Once we had that we could run different models against the files and automatically check how many of all the 324 data points matched the data in the test set to compute the model accuracy.
The Results: The Example Effect
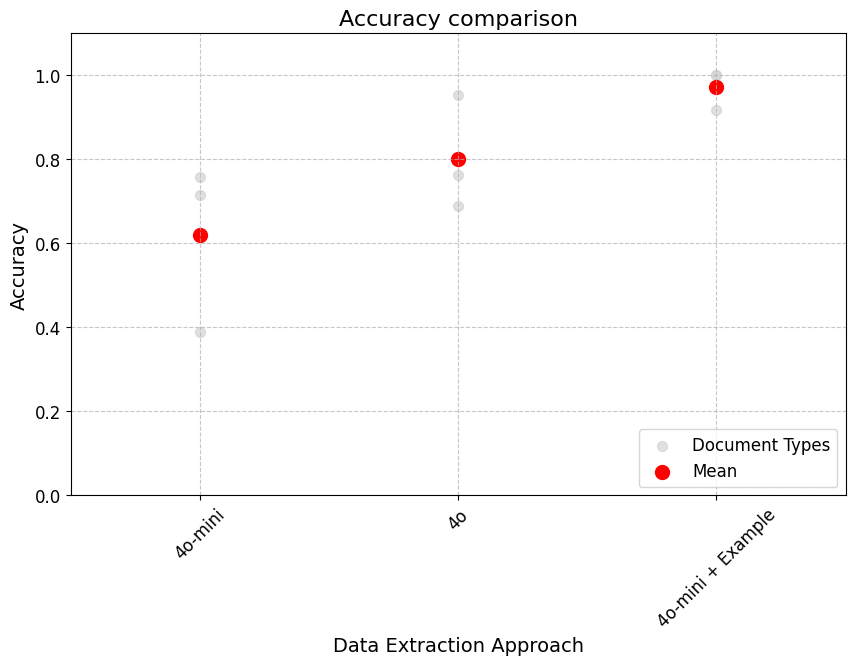
At the time we were mostly working with two model, gpt-4o-mini and gpt-4o. The first thing we try to improve the data extraction accuracy was to work on the prompt engineering. We had many iterations but even after spending a couple of hours on it we were not getting good results. With gpt-4o-mini we were at 62% accuracy, and for gpt-4o at 80% accuracy, still far for the accuracy needed for something as important as sustainability reporting. Not only the accuracy wasn't great, even if it was it would mean that we would need to have very custom prompts for each customer / data type.
Next we moved to something we have experience while testing extracting data from this documents in ChatGPT. If you gave it an example the output tended to be much better, so we tried that. For each file type we took the ground truth results from 1 out of the 12 files and send those values together with the file as part of the prompt for the other 11 files. The results were incredible! Simply adding this example to the prompt for gtp-4o-mini improved accuracy to 97%!
This results was great for two reasons:
- We could get great results using a smaller / cheaper model.
- We didn't need to look into fine-tuning or advanced document parsing techniques.
- We found an approach that was very generic and would work for many clients and use cases.
What This Means for Product Development
Beyond the increase in accuracy, these results also provide really interesting insights into what UX/UI we need to add to the product to leverage these results. If a single example can boost performance this dramatically, we need to make it dead simple for users to provide examples. Here are some approaches worth considering:
- Direct Example Input: Let users show the system what they want by providing one annotated document.
- Learning from Corrections: When users fix incorrect outputs, use those corrections as examples for future runs.
- Implicit Feedback Loop: Pay attention to user behavior – what results do they keep? What do they delete? What do they mark as favorites? This can all feed back into your example base.
In the product we implemented #1. If you want to see it in action you can start a free trial at limai.io. This approach works great in terms or results but it also adds quite some friction to the process, so currently we are exploring other alternatives as well.
The Bottom Line
As we have said before, and we will keep on saying, sometimes we overcomplicate things in AI product development. We spend weeks optimizing prompts or trying fancy architectural approaches when the answer might be as simple as showing the model what success looks like. It's a reminder that in the world of LLMs, a little show-and-tell can go a long way.
Work with us
If you found these insights interesting there are two other things that you might be interested it:
- At Limai Consulting we are starting our consulting journey. As such, over the next month we will be taking Free consulting calls to help advice companies on how to approach their AI Product Development and Strategy. If you are curious about how these techniques might apply to your own AI product development please book a free call to chat about it!
- If you are exploring data extraction products or would like to see this the impact of examples in practice head to limai.io and start a free trial of our data extraction product! By the way, we are working on a new version with a more general and interesting approach so stay tuned for that as well!